Free Statistics
of Irreproducible Research!
Description of Statistical Computation | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Author's title | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Author | *The author of this computation has been verified* | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| R Software Module | rwasp_twosampletests_mean.wasp | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Title produced by software | Paired and Unpaired Two Samples Tests about the Mean | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Date of computation | Mon, 15 Dec 2014 15:37:55 +0000 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Cite this page as follows | Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?v=date/2014/Dec/15/t1418657897ukva6v73lrptga1.htm/, Retrieved Thu, 16 May 2024 11:05:49 +0000 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?pk=268648, Retrieved Thu, 16 May 2024 11:05:49 +0000 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| QR Codes: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Original text written by user: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| IsPrivate? | No (this computation is public) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| User-defined keywords | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Estimated Impact | 91 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tree of Dependent Computations | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Family? (F = Feedback message, R = changed R code, M = changed R Module, P = changed Parameters, D = changed Data) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| - [Percentiles] [Intrinsic Motivat...] [2010-10-12 12:10:58] [b98453cac15ba1066b407e146608df68] - RMPD [Kernel Density Estimation] [] [2011-10-18 22:42:23] [b98453cac15ba1066b407e146608df68] - RMPD [Percentiles] [] [2011-10-18 22:46:45] [b98453cac15ba1066b407e146608df68] - RMPD [Notched Boxplots] [] [2011-10-18 22:58:56] [b98453cac15ba1066b407e146608df68] - RM D [Back to Back Histogram] [] [2011-10-18 23:05:48] [b98453cac15ba1066b407e146608df68] - RMPD [Back to Back Histogram] [] [2014-12-09 17:55:01] [ea990983fba95a758c0bb6d29c9aee24] - P [Back to Back Histogram] [] [2014-12-09 18:09:27] [ea990983fba95a758c0bb6d29c9aee24] - RMPD [Paired and Unpaired Two Samples Tests about the Mean] [] [2014-12-15 15:37:55] [6260c34aa94cecca073345f42e0d4b5d] [Current] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Feedback Forum | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Post a new message | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Dataset | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Dataseries X: | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
74 114 115 133 90 94 120 113 128 92 141 161 129 103 122 110 148 131 125 127 107 106 125 114 98 130 110 127 122 125 121 126 131 119 139 119 114 125 105 125 124 125 111 108 109 118 133 113 97 116 105 115 112 89 112 105 113 116 107 109 129 93 100 104 111 125 124 108 120 128 97 110 137 99 121 135 123 122 95 125 132 116 137 108 110 123 110 100 117 103 120 114 115 110 127 117 106 107 116 107 113 95 87 118 123 125 126 118 111 123 118 109 85 97 106 134 111 101 104 119 136 122 87 104 124 134 117 122 104 93 107 130 98 117 96 122 121 99 123 71 126 110 109 121 86 105 110 101 105 123 95 138 126 112 115 118 120 99 126 115 124 138 124 111 90 102 115 120 106 128 109 92 125 121 121 105 111 121 107 108 114 86 129 114 129 138 129 125 89 122 113 105 132 114 137 112 117 123 107 120 118 127 115 122 125 115 110 110 124 117 134 148 130 121 102 111 95 113 126 122 119 100 79 107 120 118 141 93 122 122 124 105 113 139 83 114 149 93 129 60 122 108 122 125 96 123 124 85 125 116 118 120 52 117 120 125 114 100 123 95 97 127 119 113 104 108 114 117 106 128 111 132 114 143 105 119 112 119 129 114 105 131 126 59 120 128 111 116 132 111 105 104 111 131 114 98 128 128 122 124 117 112 119 104 109 126 112 94 116 97 114 91 134 121 132 104 125 129 87 127 120 120 109 120 112 108 133 122 102 99 118 96 119 115 122 116 105 115 126 116 99 109 110 104 134 110 135 116 121 127 104 126 132 116 129 119 142 126 107 119 123 101 124 92 143 137 115 104 107 104 133 134 113 98 132 112 114 128 136 100 141 93 126 130 112 148 104 103 135 110 105 135 121 128 113 104 103 102 125 108 125 116 116 111 122 137 155 108 112 121 135 118 114 109 124 130 124 111 136 129 124 120 124 126 129 128 104 124 137 98 116 128 123 143 119 113 103 131 100 101 131 117 125 89 98 115 127 101 108 127 74 115 99 136 112 99 124 125 132 126 124 97 134 126 116 98 113 125 99 100 109 130 131 105 122 140 133 127 143 75 128 108 132 107 111 149 71 116 122 136 115 120 108 99 133 112 132 120 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Tables (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
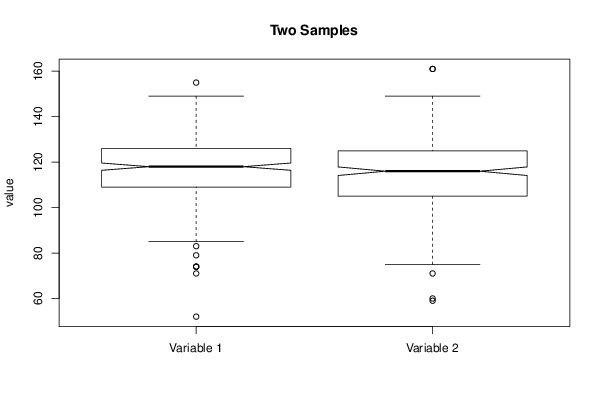
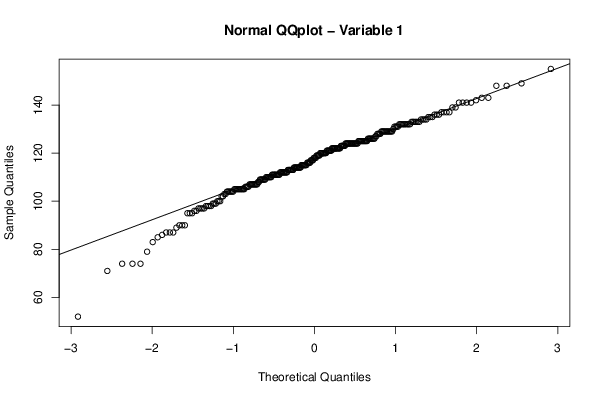
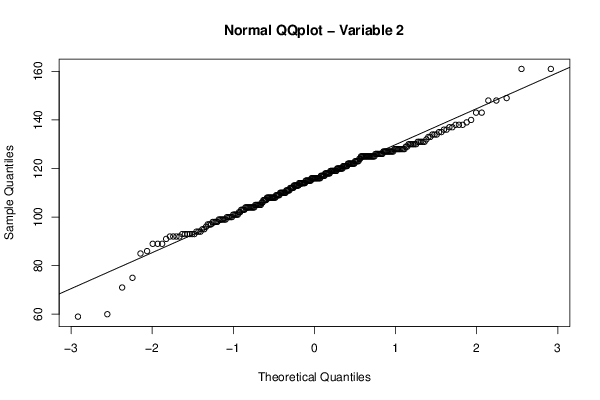
Figures (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Input Parameters & R Code | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Parameters (Session): | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| par1 = 1 ; par2 = 2 ; par3 = 0.95 ; par4 = two.sided ; par5 = unpaired ; par6 = 0.0 ; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Parameters (R input): | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| par1 = 1 ; par2 = 2 ; par3 = 0.95 ; par4 = two.sided ; par5 = unpaired ; par6 = 0.0 ; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| R code (references can be found in the software module): | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
par1 <- as.numeric(par1) #column number of first sample | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||