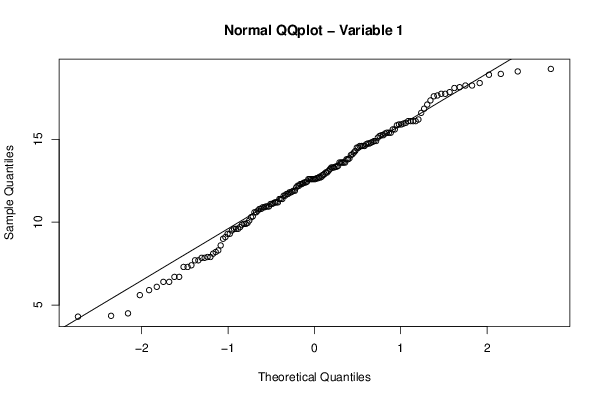
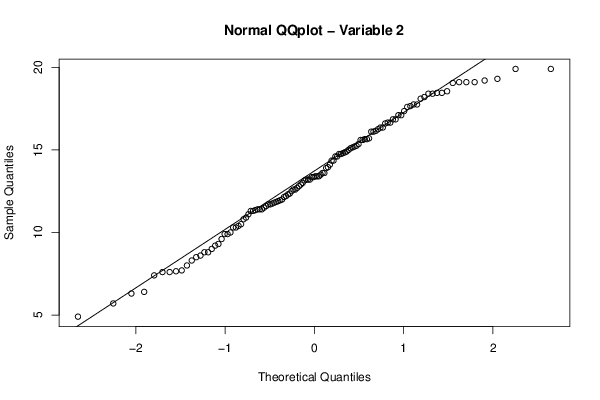
NA 12,9
NA 7,4
12,2 NA
NA 12,8
7,4 NA
6,7 NA
12,6 NA
NA 14,8
13,3 NA
11,1 NA
8,2 NA
11,4 NA
6,4 NA
10,6 NA
NA 12
NA 6,3
NA 11,3
11,9 NA
NA 9,3
9,6 NA
NA 10
6,4 NA
13,8 NA
NA 10,8
13,8 NA
11,7 NA
10,9 NA
16,1 NA
NA 13,4
9,9 NA
NA 11,5
NA 8,3
NA 11,7
6,1 NA
9 NA
9,7 NA
10,8 NA
10,3 NA
NA 10,4
12,7 NA
9,3 NA
NA 11,8
5,9 NA
11,4 NA
13 NA
10,8 NA
12,3 NA
NA 11,3
11,8 NA
7,9 NA
NA 12,7
12,3 NA
11,6 NA
6,7 NA
10,9 NA
12,1 NA
13,3 NA
10,1 NA
NA 5,7
14,3 NA
NA 8
13,3 NA
9,3 NA
NA 12,5
NA 7,6
15,9 NA
NA 9,2
9,1 NA
NA 11,1
13 NA
14,5 NA
NA 12,2
NA 12,3
NA 11,4
NA 8,8
14,6 NA
7,3 NA
NA 12,6
NA NA
NA 13
12,6 NA
NA 13,2
NA 9,9
7,7 NA
NA 10,5
NA 13,4
NA 10,9
4,3 NA
NA 10,3
11,8 NA
11,2 NA
NA 11,4
NA 8,6
NA 13,2
12,6 NA
5,6 NA
9,9 NA
NA 8,8
7,7 NA
NA 9
7,3 NA
11,4 NA
13,6 NA
7,9 NA
10,7 NA
NA 10,3
8,3 NA
9,6 NA
14,2 NA
NA 8,5
NA 13,5
NA 4,9
NA 6,4
NA 9,6
NA 11,6
11,1 NA
4,35 NA
12,7 NA
18,1 NA
17,85 NA
NA 16,6
12,6 NA
17,1 NA
NA 19,1
16,1 NA
NA 13,35
NA 18,4
14,7 NA
10,6 NA
12,6 NA
16,2 NA
13,6 NA
18,9 NA
14,1 NA
14,5 NA
NA 16,15
14,75 NA
14,8 NA
12,45 NA
12,65 NA
17,35 NA
8,6 NA
NA 18,4
16,1 NA
11,6 NA
17,75 NA
15,25 NA
17,65 NA
NA 15,6
NA 16,35
NA 17,65
13,6 NA
NA 11,7
NA 14,35
NA 14,75
18,25 NA
NA 9,9
16 NA
18,25 NA
NA 16,85
14,6 NA
13,85 NA
18,95 NA
NA 15,6
NA 14,85
NA 11,75
NA 18,45
15,9 NA
NA 17,1
16,1 NA
NA 19,9
10,95 NA
NA 18,45
15,1 NA
NA 15
NA 11,35
15,95 NA
NA 18,1
14,6 NA
15,4 NA
15,4 NA
17,6 NA
13,35 NA
NA 19,1
15,35 NA
NA 7,6
NA 13,4
NA 13,9
19,1 NA
NA 15,25
12,9 NA
NA 16,1
NA 17,35
NA 13,15
NA 12,15
12,6 NA
10,35 NA
15,4 NA
9,6 NA
NA 18,2
NA 13,6
14,85 NA
NA 14,75
NA 14,1
NA 14,9
NA 16,25
19,25 NA
13,6 NA
NA 13,6
NA 15,65
12,75 NA
NA 14,6
9,85 NA
12,65 NA
11,9 NA
NA 19,2
16,6 NA
11,2 NA
15,25 NA
NA 11,9
NA 13,2
NA 16,35
12,4 NA
15,85 NA
NA 14,35
18,15 NA
11,15 NA
NA 15,65
NA 17,75
NA 7,65
12,35 NA
15,6 NA
NA 19,3
NA 15,2
NA 17,1
15,6 NA
18,4 NA
NA 19,05
NA 18,55
NA 19,1
13,1 NA
12,85 NA
9,5 NA
4,5 NA
NA 11,85
13,6 NA
11,7 NA
12,4 NA
NA 13,35
NA 11,4
14,9 NA
NA 19,9
17,75 NA
11,2 NA
14,6 NA
NA 17,6
14,05 NA
NA 16,1
13,35 NA
11,85 NA
NA 11,95
14,75 NA
NA 15,15
13,2 NA
NA 16,85
7,85 NA
NA 7,7
NA 12,6
7,85 NA
10,95 NA
NA 12,35
9,95 NA
14,9 NA
NA 16,65
13,4 NA
NA 13,95
NA 15,7
16,85 NA
10,95 NA
NA 15,35
12,2 NA
NA 15,1
NA 17,75
15,2 NA
NA 14,6
NA 16,65
8,1 NA
|