Free Statistics
of Irreproducible Research!
Description of Statistical Computation | |||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Author's title | |||||||||||||||||||||||||||||||||||||||||||||
| Author | *Unverified author* | ||||||||||||||||||||||||||||||||||||||||||||
| R Software Module | rwasp_bidensity.wasp | ||||||||||||||||||||||||||||||||||||||||||||
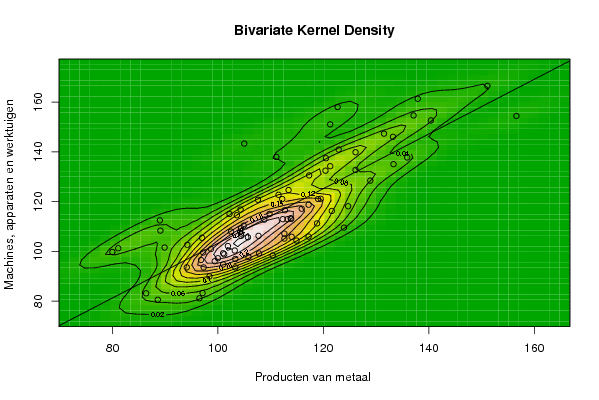
| Title produced by software | Bivariate Kernel Density Estimation | ||||||||||||||||||||||||||||||||||||||||||||
| Date of computation | Sat, 08 Nov 2008 11:58:07 -0700 | ||||||||||||||||||||||||||||||||||||||||||||
| Cite this page as follows | Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?v=date/2008/Nov/08/t1226170862blsex61y83q8aij.htm/, Retrieved Sun, 19 May 2024 02:18:15 +0000 | ||||||||||||||||||||||||||||||||||||||||||||
| Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?pk=22657, Retrieved Sun, 19 May 2024 02:18:15 +0000 | |||||||||||||||||||||||||||||||||||||||||||||
| QR Codes: | |||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||
| Original text written by user: | |||||||||||||||||||||||||||||||||||||||||||||
| IsPrivate? | No (this computation is public) | ||||||||||||||||||||||||||||||||||||||||||||
| User-defined keywords | Metaalverwerking: X:Machines, apparaten en werktuigen Y:Producten van metaal | ||||||||||||||||||||||||||||||||||||||||||||
| Estimated Impact | 170 | ||||||||||||||||||||||||||||||||||||||||||||
Tree of Dependent Computations | |||||||||||||||||||||||||||||||||||||||||||||
| Family? (F = Feedback message, R = changed R code, M = changed R Module, P = changed Parameters, D = changed Data) | |||||||||||||||||||||||||||||||||||||||||||||
| - [Mean Plot] [Mean Plot trimmin...] [2008-11-06 09:55:17] [94862dbeb1b738961deecd49975f349b] F RMPD [Bivariate Kernel Density Estimation] [Bivariate Density] [2008-11-08 18:58:07] [3b916296c2d2371d528ff188880e3d2b] [Current] | |||||||||||||||||||||||||||||||||||||||||||||
| Feedback Forum | |||||||||||||||||||||||||||||||||||||||||||||
Post a new message | |||||||||||||||||||||||||||||||||||||||||||||
Dataset | |||||||||||||||||||||||||||||||||||||||||||||
| Dataseries X: | |||||||||||||||||||||||||||||||||||||||||||||
97,3 101 113,2 101 105,7 113,9 86,4 96,5 103,3 114,9 105,8 94,2 98,4 99,4 108,8 112,6 104,4 112,2 81,1 97,1 112,6 113,8 107,8 103,2 103,3 101,2 107,7 110,4 101,9 115,9 89,9 88,6 117,2 123,9 100 103,6 94,1 98,7 119,5 112,7 104,4 124,7 89,1 97 121,6 118,8 114 111,5 97,2 102,5 113,4 109,8 104,9 126,1 80 96,8 117,2 112,3 117,3 111,1 102,2 104,3 122,9 107,6 121,3 131,5 89 104,4 128,9 135,9 133,3 121,3 120,5 120,4 137,9 126,1 133,2 151,1 105 119 140,4 156,6 137,1 122,7 | |||||||||||||||||||||||||||||||||||||||||||||
| Dataseries Y: | |||||||||||||||||||||||||||||||||||||||||||||
93,5 94,7 112,9 99,2 105,6 113 83,1 81,1 96,9 104,3 97,7 102,6 89,9 96 112,7 107,1 106,2 121 101,2 83,2 105,1 113,3 99,1 100,3 93,5 98,8 106,2 98,3 102,1 117,1 101,5 80,5 105,9 109,5 97,2 114,5 93,5 100,9 121,1 116,5 109,3 118,1 108,3 105,4 116,2 111,2 105,8 122,7 99,5 107,9 124,6 115 110,3 132,7 99,7 96,5 118,7 112,9 130,5 137,9 115 116,8 140,9 120,7 134,2 147,3 112,4 107,1 128,4 137,7 135 151 137,4 132,4 161,3 139,8 146 166,5 143,3 121 152,6 154,4 154,6 158 | |||||||||||||||||||||||||||||||||||||||||||||
Tables (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
Figures (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||
Input Parameters & R Code | |||||||||||||||||||||||||||||||||||||||||||||
| Parameters (Session): | |||||||||||||||||||||||||||||||||||||||||||||
| par1 = 50 ; par2 = 50 ; par3 = 0 ; par4 = 0 ; par5 = 0 ; par6 = Y ; par7 = Y ; | |||||||||||||||||||||||||||||||||||||||||||||
| Parameters (R input): | |||||||||||||||||||||||||||||||||||||||||||||
| par1 = 50 ; par2 = 50 ; par3 = 0 ; par4 = 0 ; par5 = 0 ; par6 = Y ; par7 = Y ; | |||||||||||||||||||||||||||||||||||||||||||||
| R code (references can be found in the software module): | |||||||||||||||||||||||||||||||||||||||||||||
par1 <- as(par1,'numeric') | |||||||||||||||||||||||||||||||||||||||||||||