Free Statistics
of Irreproducible Research!
Description of Statistical Computation | |||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Author's title | |||||||||||||||||||||||||||||||||||||||||||||
| Author | *The author of this computation has been verified* | ||||||||||||||||||||||||||||||||||||||||||||
| R Software Module | rwasp_bidensity.wasp | ||||||||||||||||||||||||||||||||||||||||||||
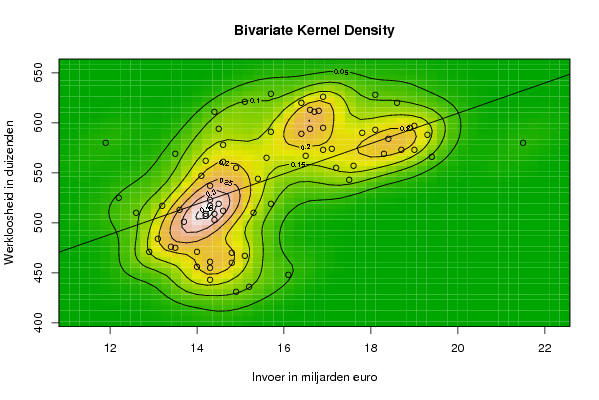
| Title produced by software | Bivariate Kernel Density Estimation | ||||||||||||||||||||||||||||||||||||||||||||
| Date of computation | Sun, 09 Nov 2008 10:40:29 -0700 | ||||||||||||||||||||||||||||||||||||||||||||
| Cite this page as follows | Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?v=date/2008/Nov/09/t1226252454gmx0ubsw5xdivmy.htm/, Retrieved Sun, 19 May 2024 02:48:09 +0000 | ||||||||||||||||||||||||||||||||||||||||||||
| Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?pk=22793, Retrieved Sun, 19 May 2024 02:48:09 +0000 | |||||||||||||||||||||||||||||||||||||||||||||
| QR Codes: | |||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||
| Original text written by user: | |||||||||||||||||||||||||||||||||||||||||||||
| IsPrivate? | No (this computation is public) | ||||||||||||||||||||||||||||||||||||||||||||
| User-defined keywords | |||||||||||||||||||||||||||||||||||||||||||||
| Estimated Impact | 181 | ||||||||||||||||||||||||||||||||||||||||||||
Tree of Dependent Computations | |||||||||||||||||||||||||||||||||||||||||||||
| Family? (F = Feedback message, R = changed R code, M = changed R Module, P = changed Parameters, D = changed Data) | |||||||||||||||||||||||||||||||||||||||||||||
| F [Bivariate Kernel Density Estimation] [invoer - werkloos...] [2008-11-09 17:40:29] [54ae75b68e6a45c6d55fa4235827d5b3] [Current] | |||||||||||||||||||||||||||||||||||||||||||||
| Feedback Forum | |||||||||||||||||||||||||||||||||||||||||||||
Post a new message | |||||||||||||||||||||||||||||||||||||||||||||
Dataset | |||||||||||||||||||||||||||||||||||||||||||||
| Dataseries X: | |||||||||||||||||||||||||||||||||||||||||||||
15,1 14,8 16,1 14,3 15,2 14,9 13,1 12,6 13,6 14,4 14 12,9 13,4 13,5 14,8 14,3 14,3 14 13,2 12,2 14,3 15,7 14,2 14,6 14,5 14,3 15,3 14,4 13,7 14,2 13,5 11,9 14,6 15,6 14,1 14,9 14,2 14,6 17,2 15,4 14,3 17,5 14,5 14,4 16,6 16,7 16,6 16,9 15,7 16,4 18,4 16,9 16,5 18,3 15,1 15,7 18,1 16,8 18,9 19 18,1 17,8 21,5 17,1 18,7 19 16,4 16,9 18,6 19,3 19,4 17,6 | |||||||||||||||||||||||||||||||||||||||||||||
| Dataseries Y: | |||||||||||||||||||||||||||||||||||||||||||||
467 460 448 443 436 431 484 510 513 503 471 471 476 475 470 461 455 456 517 525 523 519 509 512 519 517 510 509 501 507 569 580 578 565 547 555 562 561 555 544 537 543 594 611 613 611 594 595 591 589 584 573 567 569 621 629 628 612 595 597 593 590 580 574 573 573 620 626 620 588 566 557 | |||||||||||||||||||||||||||||||||||||||||||||
Tables (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
Figures (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||||||
Input Parameters & R Code | |||||||||||||||||||||||||||||||||||||||||||||
| Parameters (Session): | |||||||||||||||||||||||||||||||||||||||||||||
| par1 = 50 ; par2 = 50 ; par3 = 0 ; par4 = 0 ; par5 = 0 ; par6 = Y ; par7 = Y ; | |||||||||||||||||||||||||||||||||||||||||||||
| Parameters (R input): | |||||||||||||||||||||||||||||||||||||||||||||
| par1 = 50 ; par2 = 50 ; par3 = 0 ; par4 = 0 ; par5 = 0 ; par6 = Y ; par7 = Y ; | |||||||||||||||||||||||||||||||||||||||||||||
| R code (references can be found in the software module): | |||||||||||||||||||||||||||||||||||||||||||||
par1 <- as(par1,'numeric') | |||||||||||||||||||||||||||||||||||||||||||||