Free Statistics
of Irreproducible Research!
Description of Statistical Computation | |||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Author's title | |||||||||||||||||||||||||||||||||||||||
| Author | *The author of this computation has been verified* | ||||||||||||||||||||||||||||||||||||||
| R Software Module | rwasp_fitdistrnorm.wasp | ||||||||||||||||||||||||||||||||||||||
| Title produced by software | Maximum-likelihood Fitting - Normal Distribution | ||||||||||||||||||||||||||||||||||||||
| Date of computation | Thu, 13 Nov 2008 01:47:07 -0700 | ||||||||||||||||||||||||||||||||||||||
| Cite this page as follows | Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?v=date/2008/Nov/13/t1226566065y2wegqihk1te1vx.htm/, Retrieved Sun, 19 May 2024 02:45:20 +0000 | ||||||||||||||||||||||||||||||||||||||
| Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?pk=24486, Retrieved Sun, 19 May 2024 02:45:20 +0000 | |||||||||||||||||||||||||||||||||||||||
| QR Codes: | |||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||
| Original text written by user: | |||||||||||||||||||||||||||||||||||||||
| IsPrivate? | No (this computation is public) | ||||||||||||||||||||||||||||||||||||||
| User-defined keywords | natalie en evelyn | ||||||||||||||||||||||||||||||||||||||
| Estimated Impact | 211 | ||||||||||||||||||||||||||||||||||||||
Tree of Dependent Computations | |||||||||||||||||||||||||||||||||||||||
| Family? (F = Feedback message, R = changed R code, M = changed R Module, P = changed Parameters, D = changed Data) | |||||||||||||||||||||||||||||||||||||||
| - [Box-Cox Linearity Plot] [Box-Cox] [2008-11-11 14:29:04] [adb6b6905cde49db36d59ca44433140d] F RMPD [Maximum-likelihood Fitting - Normal Distribution] [Maximum likehood ...] [2008-11-11 15:10:16] [adb6b6905cde49db36d59ca44433140d] F D [Maximum-likelihood Fitting - Normal Distribution] [Maximum-likelihoo...] [2008-11-11 23:51:03] [b591abfa820a394aeb0c5ebd9cfa1091] F D [Maximum-likelihood Fitting - Normal Distribution] [normal distribution] [2008-11-13 08:47:07] [32a7b12f2bdf14b45f7a9a96ba1ab98d] [Current] | |||||||||||||||||||||||||||||||||||||||
| Feedback Forum | |||||||||||||||||||||||||||||||||||||||
Post a new message | |||||||||||||||||||||||||||||||||||||||
Dataset | |||||||||||||||||||||||||||||||||||||||
| Dataseries X: | |||||||||||||||||||||||||||||||||||||||
519164 517009 509933 509127 500857 506971 569323 579714 577992 565464 547344 554788 562325 560854 555332 543599 536662 542722 593530 610763 612613 611324 594167 595454 590865 589379 584428 573100 567456 569028 620735 628884 628232 612117 595404 597141 593408 590072 579799 574205 572775 572942 619567 625809 619916 587625 565742 557274 560576 548854 531673 525919 511038 498662 555362 564591 541657 527070 509846 514258 | |||||||||||||||||||||||||||||||||||||||
Tables (Output of Computation) | |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
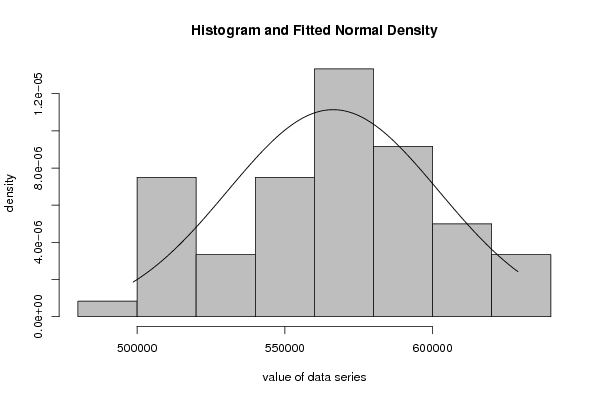
Figures (Output of Computation) | |||||||||||||||||||||||||||||||||||||||
Input Parameters & R Code | |||||||||||||||||||||||||||||||||||||||
| Parameters (Session): | |||||||||||||||||||||||||||||||||||||||
| par1 = 8 ; par2 = 0 ; | |||||||||||||||||||||||||||||||||||||||
| Parameters (R input): | |||||||||||||||||||||||||||||||||||||||
| par1 = 8 ; par2 = 0 ; | |||||||||||||||||||||||||||||||||||||||
| R code (references can be found in the software module): | |||||||||||||||||||||||||||||||||||||||
library(MASS) | |||||||||||||||||||||||||||||||||||||||