Free Statistics
of Irreproducible Research!
Description of Statistical Computation | |||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Author's title | |||||||||||||||||||||||||||||||||||||||||
| Author | *The author of this computation has been verified* | ||||||||||||||||||||||||||||||||||||||||
| R Software Module | rwasp_univariatedataseries.wasp | ||||||||||||||||||||||||||||||||||||||||
| Title produced by software | Univariate Data Series | ||||||||||||||||||||||||||||||||||||||||
| Date of computation | Sun, 23 Nov 2008 14:53:33 -0700 | ||||||||||||||||||||||||||||||||||||||||
| Cite this page as follows | Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?v=date/2008/Nov/23/t1227477278rq1w6gc9xoc51om.htm/, Retrieved Sun, 19 May 2024 08:04:27 +0000 | ||||||||||||||||||||||||||||||||||||||||
| Statistical Computations at FreeStatistics.org, Office for Research Development and Education, URL https://freestatistics.org/blog/index.php?pk=25346, Retrieved Sun, 19 May 2024 08:04:27 +0000 | |||||||||||||||||||||||||||||||||||||||||
| QR Codes: | |||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||
| Original text written by user: | |||||||||||||||||||||||||||||||||||||||||
| IsPrivate? | No (this computation is public) | ||||||||||||||||||||||||||||||||||||||||
| User-defined keywords | |||||||||||||||||||||||||||||||||||||||||
| Estimated Impact | 183 | ||||||||||||||||||||||||||||||||||||||||
Tree of Dependent Computations | |||||||||||||||||||||||||||||||||||||||||
| Family? (F = Feedback message, R = changed R code, M = changed R Module, P = changed Parameters, D = changed Data) | |||||||||||||||||||||||||||||||||||||||||
| - [Univariate Data Series] [Werkloosheid BELGIE] [2008-10-19 10:57:42] [46c5a5fbda57fdfa1d4ef48658f82a0c] - PD [Univariate Data Series] [Task 6, Q3, 1] [2008-11-21 11:06:34] [70cb582895831af4be81fec73c607e93] F PD [Univariate Data Series] [Task 6, Q3, 1] [2008-11-21 11:17:50] [70cb582895831af4be81fec73c607e93] F PD [Univariate Data Series] [Taak 6, Q3, 1] [2008-11-23 21:53:33] [dbfa7caa6871c163dec68ca05d48bb00] [Current] - RMPD [Multiple Regression] [Verbetering evely...] [2008-11-28 08:35:08] [077ffec662d24c06be4c491541a44245] - P [Multiple Regression] [verbetering evely...] [2008-11-28 09:04:44] [077ffec662d24c06be4c491541a44245] - P [Multiple Regression] [verbetering evely...] [2008-11-28 09:16:12] [077ffec662d24c06be4c491541a44245] | |||||||||||||||||||||||||||||||||||||||||
| Feedback Forum | |||||||||||||||||||||||||||||||||||||||||
Post a new message | |||||||||||||||||||||||||||||||||||||||||
Dataset | |||||||||||||||||||||||||||||||||||||||||
| Dataseries X: | |||||||||||||||||||||||||||||||||||||||||
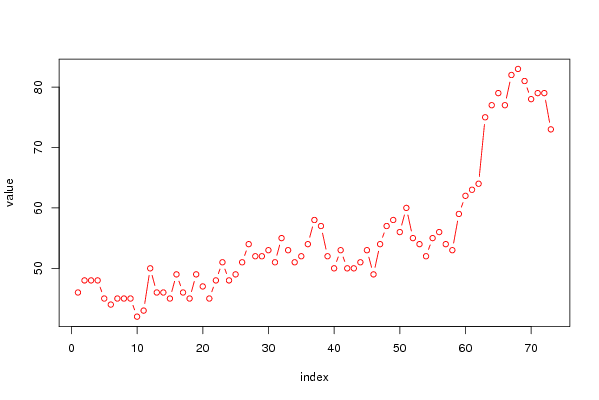
46 48 48 48 45 44 45 45 45 42 43 50 46 46 45 49 46 45 49 47 45 48 51 48 49 51 54 52 52 53 51 55 53 51 52 54 58 57 52 50 53 50 50 51 53 49 54 57 58 56 60 55 54 52 55 56 54 53 59 62 63 64 75 77 79 77 82 83 81 78 79 79 73 | |||||||||||||||||||||||||||||||||||||||||
Tables (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||
Figures (Output of Computation) | |||||||||||||||||||||||||||||||||||||||||
Input Parameters & R Code | |||||||||||||||||||||||||||||||||||||||||
| Parameters (Session): | |||||||||||||||||||||||||||||||||||||||||
| par1 = Ontwikkeling prijzen in Belgi� ; par2 = http://www.nbb.be/belgostat/PublicatieSelectieLinker?LinkID=117000047|910000082&Lang=N ; par3 = Periode 2003-10 - 2008-09 ; | |||||||||||||||||||||||||||||||||||||||||
| Parameters (R input): | |||||||||||||||||||||||||||||||||||||||||
| par1 = Ontwikkeling prijzen in Belgi� ; par2 = http://www.nbb.be/belgostat/PublicatieSelectieLinker?LinkID=117000047|910000082&Lang=N ; par3 = Periode 2003-10 - 2008-09 ; | |||||||||||||||||||||||||||||||||||||||||
| R code (references can be found in the software module): | |||||||||||||||||||||||||||||||||||||||||
bitmap(file='test1.png') | |||||||||||||||||||||||||||||||||||||||||