par1 <- as.numeric(par1)
par2 <- as.numeric(par2)
x <- as.ts(x)
library(lattice)
bitmap(file='pic1.png')
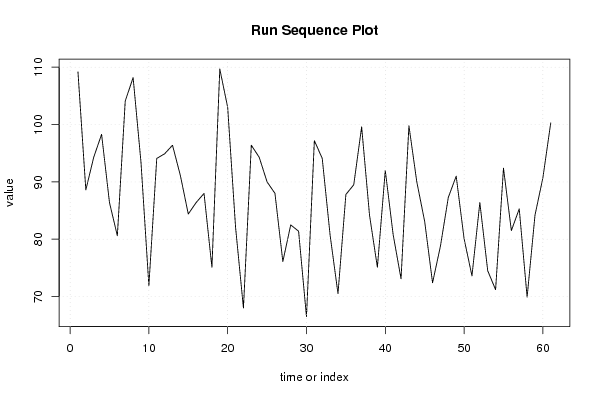
plot(x,type='l',main='Run Sequence Plot',xlab='time or index',ylab='value')
grid()
dev.off()
bitmap(file='pic2.png')
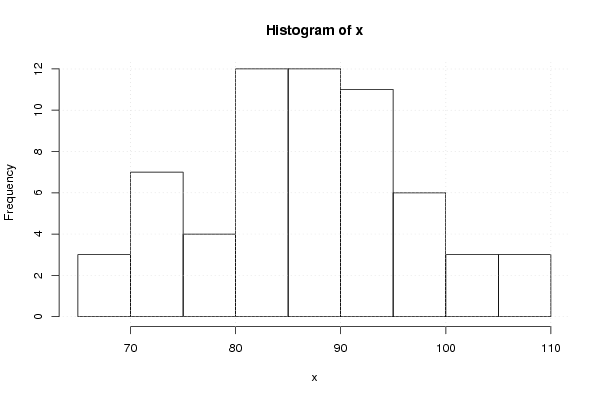
hist(x)
grid()
dev.off()
bitmap(file='pic3.png')
if (par1 > 0)
{
densityplot(~x,col='black',main=paste('Density Plot bw = ',par1),bw=par1)
} else {
densityplot(~x,col='black',main='Density Plot')
}
dev.off()
bitmap(file='pic4.png')
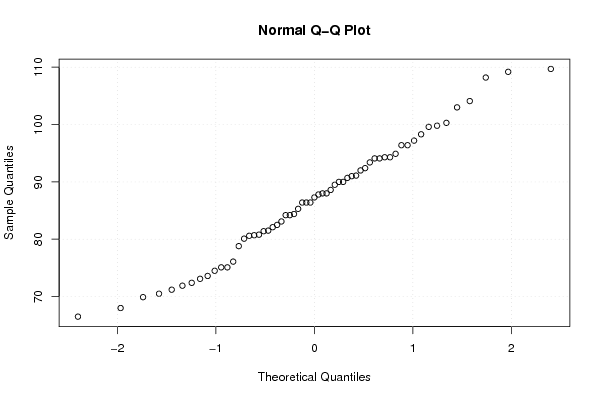
qqnorm(x)
grid()
dev.off()
if (par2 > 0)
{
bitmap(file='lagplot.png')
dum <- cbind(lag(x,k=1),x)
dum
dum1 <- dum[2:length(x),]
dum1
z <- as.data.frame(dum1)
z
plot(z,main=paste('Lag plot, lowess, and regression line'))
lines(lowess(z))
abline(lm(z))
dev.off()
bitmap(file='pic5.png')
acf(x,lag.max=par2,main='Autocorrelation Function')
grid()
dev.off()
}
summary(x)
load(file='createtable')
a<-table.start()
a<-table.row.start(a)
a<-table.element(a,'Descriptive Statistics',2,TRUE)
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'# observations',header=TRUE)
a<-table.element(a,length(x))
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'minimum',header=TRUE)
a<-table.element(a,min(x))
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'Q1',header=TRUE)
a<-table.element(a,quantile(x,0.25))
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'median',header=TRUE)
a<-table.element(a,median(x))
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'mean',header=TRUE)
a<-table.element(a,mean(x))
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'Q3',header=TRUE)
a<-table.element(a,quantile(x,0.75))
a<-table.row.end(a)
a<-table.row.start(a)
a<-table.element(a,'maximum',header=TRUE)
a<-table.element(a,max(x))
a<-table.row.end(a)
a<-table.end(a)
table.save(a,file='mytable.tab')
|